英特尔提供Loihi 2神经形态芯片和软件框架
英特尔推出了第二代神经形态计算芯片Loihi 2,这是第一款基于英特尔4工艺技术的芯片。专为研究尖端神经形态神经网络,Loihi 2带来了一系列改进。它们包括一个新的神经元指令集,它提供了更多的可编程性,允许尖峰具有超过1和0的整数值,并能...
英特尔推出了第二代神经形态计算芯片Loihi 2,这是第一款基于英特尔4工艺技术的芯片。专为研究尖端神经形态神经网络,Loihi 2带来了一系列改进。它们包括一个新的神经元指令集,它提供了更多的可编程性,允许尖峰具有超过1和0的整数值,并能够扩展到更大系统的芯片三维网格中。
这家芯片制造商还推出了Lava,这是一个用于开发神经启发应用程序的开源软件框架。英特尔希望让神经形态研究人员参与熔岩的开发,当熔岩启动并运行时,研究团队将能够在彼此的工作基础上再接再厉。
Loihi是英特尔的神经形态硬件版本,专为受大脑启发的尖峰神经网络(SNN)设计。SNN用于基于事件的计算,其中输入尖峰的定时对信息进行编码。一般来说,较早到达的尖峰比较晚到达的尖峰具有更大的计算效果。

<img data-lazy-fallback="1" decoding="async" src="https://uploads.9icnet.com/images/aritcle/20230418/Intel-Loihi-2-die-2.jpg">
英特尔的Loihi 2第二代神经形态处理器。(资料来源:英特尔)
神经形态硬件和标准CPU之间的关键区别之一是内存的细粒度分布,这意味着Loihi的内存嵌入到各个内核中。由于Loihi的尖峰依赖于定时,因此该体系结构是异步的。
解释道:“在神经形态计算中,计算是通过这些动力学元素之间的相互作用而出现的。”麦克·戴维斯英特尔神经形态计算实验室主任。“在这种情况下,神经元具有在线适应输入的动态特性,程序员可能不知道芯片需要经过哪些步骤才能得出答案。
戴维斯补充道:“它经历了一个自组织状态的动态过程,并适应了一些新的条件。我们称之为平衡状态的最后一个不动点,就是你想要解决的问题的答案。”。“因此,这与我们在其他架构中对计算的看法有着根本的不同。”
到目前为止,第一代Loihi芯片已在各种研究应用中得到验证,包括自适应机械臂控制,其中运动适应系统的变化,减少手臂上的摩擦和磨损。Loihi能够调整其控制算法,以补偿误差或不可预测的行为,使机器人能够以所需的精度运行。Loihi也被用于识别不同气味的系统。在这种情况下,它可以比基于深度学习的同类产品更有效地学习和检测新气味。德国铁路公司的一个项目也使用Loihi进行列车调度。该系统对轨道关闭或列车停运等变化反应迅速。
第二代功能
Loihi 2建立在英特尔4工艺的预生产版本上,旨在提高可编程性和性能,同时又不影响能源效率。与它的前代产品一样,它通常消耗大约100 mW(高达1 W)。
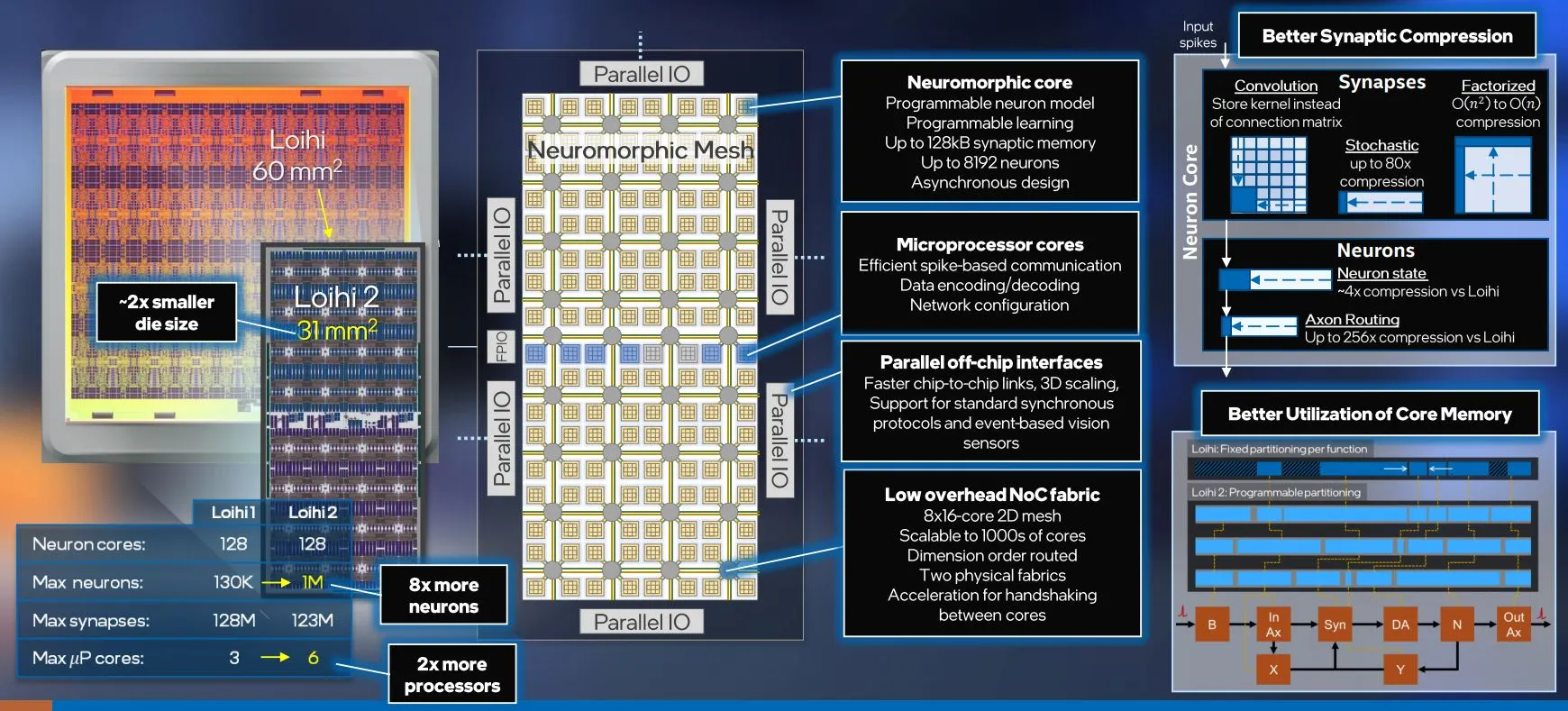
资源密度的增加是最重要的变化之一;虽然该芯片仍包含128个核心,但神经元数量增加了8倍。
戴维斯说:“在单个芯片中获得更高数量的存储、神经元和突触对于商业可行性至关重要……并以对客户应用有意义的方式将其商业化。”。
<img data-lazy-fallback="1" decoding="async" style="width: 600px; margin-left: auto; margin-right: auto;" src="https://uploads.9icnet.com/images/aritcle/20230418/Intel-Loihi2-slide1.jpg">
Loihi 2功能。(资料来源:英特尔)
对于Loihi 1,工作负载通常会以非最优的方式映射到体系结构上。例如,当空闲内存仍然可用时,神经元计数通常会达到最大值。Loihi 2中的内存总量相似,但已分解为更灵活的内存组。对网络参数添加了额外的压缩,以最大限度地减少大型模型所需的内存量。这释放了可以重新分配给神经元的内存。
结果是,Loihi 2可以在相同的内存量下解决更大的问题,每毫米神经网络容量增加约15倍2.芯片面积的减少–请记住,新工艺技术使芯片面积减少了一半。
神经元可编程性
可编程性是另一个重要的体系结构修改。之前在Loihi 1中固定功能的神经元,尽管可以配置,但在Loihii 2中获得完整的指令集。指令集包括常见的算术、比较和程序控制流指令。这种级别的可编程性将允许更有效地运行各种SNN类型。
戴维斯说:“这是一种微代码,可以让我们对几乎任意的神经元模型进行编程。”。“这涵盖了Loihi[1]的局限性,通常我们发现,通过更复杂、更丰富的神经元模型可以解锁更多的应用价值,这不是我们在Loihi一开始所期望的。但现在我们实际上可以涵盖我们的合作伙伴正试图研究的全部神经元模型,以及计算神经科学领域提出和描述。”

<img data-lazy-fallback="1" decoding="async" src="https://uploads.9icnet.com/images/aritcle/20230418/Intel-Loihi-2-die.jpg">
Loihi 2芯片是第一个采用英特尔4工艺技术的预生产版本制造的芯片。(资料来源:英特尔)
对于Loihi 2,尖峰的概念也得到了推广。Loihi 1采用了严格的二进制尖峰来反映生物学中看到的情况,在生物学中尖峰没有大小。所有信息都由尖峰定时表示,并且较早的尖峰将比较晚的尖峰具有更大的计算效果。在Loihi 2中,尖峰携带可编程神经元模型可用的可配置整数有效载荷。戴维斯说,虽然生物大脑不能做到这一点,但英特尔在不影响性能的情况下,将其添加到硅架构中相对容易。
他说:“这是一个我们偏离严格生物保真度的例子,特别是因为我们了解它的重要性,以及它的时间编码方面。”。“但(我们意识到)我们可以做得更好,如果我们有这种额外的规模,可以与这一峰值一起发送,我们可以用更少的资源解决同样的问题。”
基于广义事件的消息传递是Loihi 2支持称为西格玛-德尔塔神经网络(SDNN)的深度神经网络的关键,该网络比Loihi 1上使用的计时方法快得多。SDNN以与传统DNN相同的方式计算分级激活值,但仅在以稀疏、事件驱动的方式发生重大变化时进行通信。
三维缩放
Loihi 2被宣传为在电路级别上比其前身快10倍。戴维斯声称,结合功能改进,该设计可以实现高达10倍的速度提升。Loihi 2支持200ns以下的最小芯片宽度时间步长;它处理神经形态网络的速度比生物神经元快5000倍。
新芯片还具有可扩展端口,使英特尔能够将神经网络扩展到第三维度。由于没有外部存储器来运行更大的神经网络,Loihi 1需要多个设备(如英特尔的768 Loihi芯片系统,Pohoiki Springs). Loihi 1芯片的平面网格在Loihi 2中变为3D网格。与此同时,芯片到芯片的带宽提高了四倍,压缩和新协议提供了芯片之间发送的冗余尖峰流量的十分之一。Davies表示,大多数工作负载的综合容量提高了约60倍,避免了芯片间链路造成的瓶颈。
还支持三因素学习,这在尖端的神经形态算法研究中很受欢迎。同样的修改将第三因素映射到特定的突触,可以用来近似反向传播,这是深度学习中使用的训练方法。这创造了通过Loihi学习的新方式。

<img data-lazy-fallback="1" decoding="async" style="width: 600px; margin-left: auto; margin-right: auto;" src="https://uploads.9icnet.com/images/aritcle/20230418/Intel-Loihi2-Systems.jpg">
Loihi 2将作为开发边缘应用程序的单芯片板(Oheo Gulch)提供给研究人员。它还将作为八芯片板提供,旨在扩展到更苛刻的应用。(资料来源:英特尔)
熔岩
Lava软件框架完善了Loihi增强功能。该开源项目可供神经形态研究社区使用。
戴维斯说:“软件继续阻碍着这一领域的发展。”。“在过去几年里,没有取得太多进展,速度与硬件不同。也没有出现单一的软件框架,正如我们在深度学习世界中看到的那样,TensorFlow和PyTorch正在聚集巨大的势头和用户群。”
虽然英特尔为Loihi展示了一系列应用程序,但开发团队之间的代码共享受到了限制。这使得开发人员更难在其他地方取得的进展的基础上再接再厉。
Davies表示,Lava被宣传为一个新项目,而不是一个产品,旨在建立一个框架,支持Loihi研究人员研究一系列算法。虽然Lava的目标是基于事件的异步消息传递,但它也将支持异构执行。这使得研究人员能够开发最初在CPU上运行的应用程序。通过访问Loihi硬件,研究人员可以将部分工作负载映射到神经形态芯片上。希望这种方法将有助于降低进入壁垒。
戴维斯说:“我们看到,为了实现这一更大的目标,需要融合和共同发展,这对于神经形态技术的商业化是必要的。”。
Loihi 2将被开发高级神经形态算法的研究人员使用。Oheo Gulch是一种用于实验室测试的单芯片系统,最初将提供给研究人员,随后是Kapoho Point,一种八芯片Loihi 2版本的Kapoho Bay。Kapoho Point包括一个以太网接口,设计用于堆叠板,用于需要更多计算能力的机器人等应用。
Lava可在上下载github.
>>这篇文章最初发表在我们的姐妹网站上,EE时间.
