
为什么要在一台设备上训练一个200亿参数的人工智能模型?
Cerebras的晶圆级引擎创造了在单个芯片上训练最大人工智能模型的记录。为什么这很重要? Cerebras展示了其第二代晶圆级引擎的能力,宣布其创下了有史以来在单个设备上训练的最大人工智能模型的记录。 首次在单个设备上训练了一个具有200...
Cerebras展示了其第二代晶圆级引擎的能力,宣布其创下了有史以来在单个设备上训练的最大人工智能模型的记录。
首次在单个设备上训练了一个具有200亿个参数的自然语言处理网络GPT–NeoX 20B。这就是为什么这很重要。
为什么我们需要训练这么大的模特?
一种新型的神经网络,变压器,正在取而代之。如今,转换器主要用于自然语言处理(NLP),它们的注意力机制可以帮助发现句子中单词之间的关系,但它们正在向其他人工智能应用,包括视觉。转换器越大,它就越准确。语言模型现在通常有数十亿个参数,而且它们正在迅速增长,没有任何放缓的迹象。
巨大的转换器正在被使用的一个关键领域是在表观基因组学等应用的医学研究中,它们被用来模拟基因的“语言”——DNA序列。
为什么在一台设备上完成这项工作很重要?
如今,大型模型大多使用多处理器系统(通常是GPU)进行训练。Cerebras表示,其客户发现,根据模型的属性和每个处理器的特性(即它是什么类型的处理器,有多少内存)以及I/O网络的特性,在数百个处理器之间划分巨大的模型是一个耗时的过程,这对每个模型和每个特定的多处理器系统来说都是独一无二的。这项工作不能移植到其他模型或系统。
通常,对于多处理器系统,有三种类型的并行性在发挥作用:
巨大的模型,如Cerebras公告中的GPT–NeoX 20B,需要所有三种类型的并行性来进行训练。
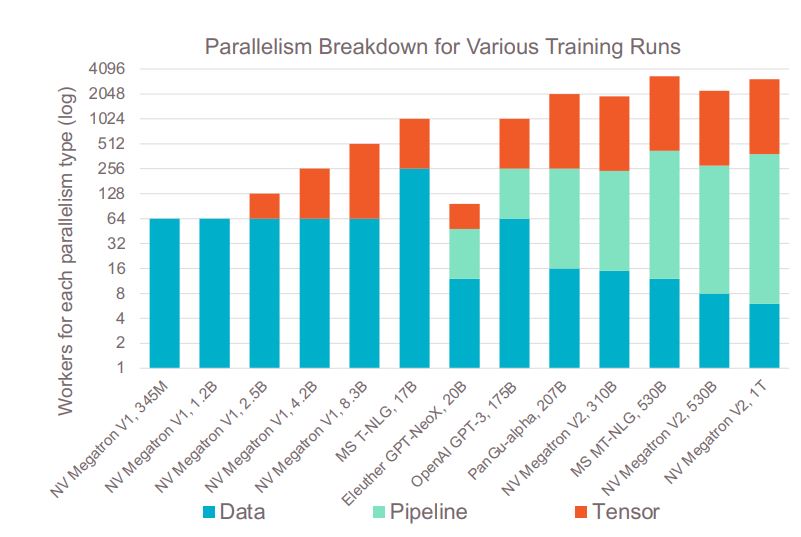
当今用于训练大型模型的并行类型的细分(来源:Cerebras)
Cerebras的CS–2避免了对模型进行并行化的需要,部分原因是其处理器的巨大尺寸——它实际上是一个巨大的850000个核心处理器,单个晶圆大小的芯片即使是最大的网络层也足够大,部分原因是Cerebras将内存从计算中分解出来。可以添加更多的内存来支持更多的参数,而不需要添加更多的计算,从而保持系统的计算部分的架构相同。

Cerebras的WSE–2,其CS–2系统中的处理器,有餐盘那么大(来源:Cerebras)
如果不需要使用并行性,就不需要花费时间和资源手动划分模型以在多处理器系统上运行。此外,在没有定制部分的过程中,模型变得可移植。在具有多个参数的GPT模型之间进行更改只需要在一个文件中更改四个变量。类似地,在GPT–J和GPT–Neo之间切换只需要几次按键。根据Cerebras的说法,这可以节省数月的工程时间。
对更广泛的行业有什么影响?
NLP模型已经发展得如此之大,以至于在实践中,只有少数公司有足够的资源来训练它们,无论是在计算成本还是工程时间方面。
Cerebras希望,通过在云中提供其CS–2系统,以及帮助客户减少所需的工程时间和资源,它可以为更多的公司,甚至那些没有庞大系统工程团队的公司,提供大规模的模型培训。这包括加速科学和医学研究以及NLP。
一个CS–2可以训练具有数千亿甚至数万亿参数的模型,因此明天的巨大网络和今天的网络都有很大的空间。
Cerebras有真实世界的例子吗?
生物制药公司AbbVie正在使用CS–2进行生物医学NLP转换器培训,这为该公司的翻译服务提供了动力,使大量生物医学文献库可以在180种语言中进行搜索。
“我们在编程和培训BERT方面遇到的共同挑战大型生物制药公司AbbVie的人工智能主管Brian Martin在一份声明中表示:“模型在足够的时间内提供了足够的GPU集群资源。“CS–2系统将提供墙上的时钟改进,在很大程度上缓解这一挑战,同时提供一个更简单的编程模型,使我们的团队能够更快地迭代和测试更多的想法,从而加速我们的交付。”
葛兰素史克公司使用了第一代小脑系统CS–1,用于表观基因组学研究该系统能够用数据集训练网络,否则数据集会非常大。
GSK人工智能和机器学习高级副总裁Kim Branson在一份声明中表示:“GSK通过其基因组和基因研究生成了极其庞大的数据集,这些数据集需要新的设备来进行机器学习。”。“Cerebras CS–2是一个关键组件,它使葛兰素史克能够以以前无法达到的规模和大小使用生物数据集训练语言模型。这些基础模型构成了我们许多人工智能系统的基础,并在发现转化药物方面发挥着至关重要的作用。”
其他Cerebras用户包括TotalEnergies,他们使用CS–2来加速电池、生物燃料、气流、钻井和一氧化碳的模拟2.存储国家能源技术实验室用CS–2加速基于物理的计算流体动力学;阿贡国家实验室(Argonne National Laboratory)一直在使用一种CS–1,用于新冠肺炎-19研究和癌症药物;还有更多的例子。
>>这篇文章最初发表在我们的姐妹网站上,EE时间.