
NVIDIA和微软联手开发海量云人工智能计算机
上周,微软和NVIDIA宣布合作开发最强大、可大规模扩展的人工智能虚拟机。2022年11月28日作者:Darshil Patel
2019年,微软与OpenAI合作,构建了一台在Azure云上运行的基于云的人工智能超级计算机。它是世界上公开披露的五大超级计算机之一。同年,微软分享了其对“大规模人工智能”的愿景,并开始研究一类处理1000多亿个参数的新技术。
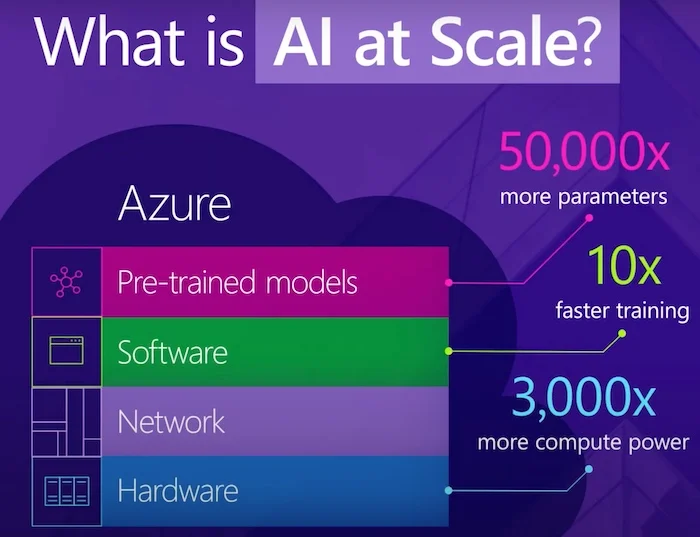
微软的“大规模人工智能”方法。屏幕截图由微软提供
为了支持更雄心勃勃的人工智能工作负载,微软现在与NVIDIA合作,作为多年合作的一部分,以构建一台新的超级计算机,该计算机运行在Azure的超级计算基础设施上,由NVIDIA GPU(图形处理单元)、网络平台和人工智能软件提供动力。新的超级计算机将有助于加速生成人工智能的发展,并使企业能够训练和部署大规模模型。
与此同时,微软将利用NVIDIA强大的转换器引擎NVIDIA H100来优化其基于转换器的大型语言模型库DeepSpeed,从而减少其在人工智能训练过程中的能耗和内存使用。两家公司还将制作一系列人工智能工作流和软件开发工具包,供Azure Enterprise客户使用。
新型云人工智能计算机
新的基于云的人工智能计算机具有针对人工智能工作负载优化的可扩展Azure ND和NC系列虚拟机。在硬件层面,它包括数千个NVIDIA Quantum InfiniBand平台和NVIDIA AI Enterprise软件套件。

NVIDIA H100 Tensor Core GPU。图像由NVIDIA提供
Microsoft Azure的AI虚拟机现在集成了NVIDIA的高级GPU和网络平台,因此Azure客户可以在单个集群中部署数千个GPU来训练大规模建模。这些公司还声称,他们的服务允许大规模生成人工智能。
当前的Azure虚拟机采用NVIDIA Quantum 200 Gb/s网络平台和NVIDIA A100 GPU。它将升级为Quantum-2 400 Gb/s InfiniBand网络和NVIDIA H100 GPU。H100 GPU拥有第四代张量核心,具有FP8精度的Transformer Engine提供的训练速度是A100 GPU的九倍。
大规模人工智能和生成型人工智能
大规模人工智能是微软快速训练大规模机器学习模型的并行计算新方法。大型、集中的人工智能模型是有利的,因为它们只需要使用具有海量数据集的超级计算进行一次训练。它们还可以针对不同的任务和域进行微调。这样的模型可以在各种产品中进行缩放和修改。
凭借其170亿参数的图灵自然语言生成(T-NLG)模型,微软展示了检测数据细微差别的能力。然而,训练这样的模型需要数千台人工智能加速机器集群,通过整个数据中心的高带宽网络互连。微软提到,Azure中的此类集群能够在微软产品中生成和理解新的自然语言。
T-NLG在许多下游NLP任务上优于其他模型。图片由微软提供[点击放大]
现在,借助NVIDIA的H100 Transformer Engine和Quantum InfiniBand网络平台,两家公司的目标都是加速Azure的DeepSpeed语言模型。新硬件将实现8位浮点精度,使DeepSpeed中16位操作的吞吐量翻一番。NVIDIA AI Enterprise软件套件还通过简化人工智能工作负载,在生成人工智能和其他网络安全框架方面发挥着重要作用。
Azure虚拟机系列ND A100 v4和集群现在正在预览中,它将成为一种标准产品,允许在数百台虚拟机上配置从8到数千个互连NVIDIA GPU的任何大小的集群。