
仙女座上的计算:芯片公司发布13.5M核心超级计算机
Cerebras以其餐盘大小的人工智能芯片而闻名,现已发布了一款可用于商业和学术研究的人工智能超级计算机。2022年11月17日,作者:Chantelle Dubois
人工智能公司Cerebras最近推出了专门针对深度学习应用进行优化的仙女座超级计算机。据称,仙女座的核心数量超过1953个NVIDIA A100 GPU,核心数量是Frontier超级计算机的1.6倍。
该公司正试图消除通用计算平台的常见挑战,例如在分布式GPU集群上实现培训所需的额外开销。一些分布式系统会导致工程师难以解决的3D配置。
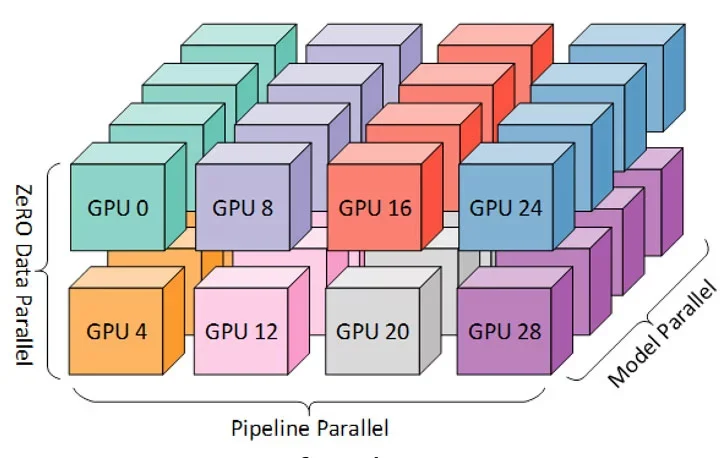
分布式通用GPU中的3D并行性。
Cerebras最近发布了其仙女座超级计算机,包括一个人工智能应用程序专用硬件架构,可以在几个GPT语言模型上提供线性缩放训练;简单地说,训练时间随着所涉及的计算核心的数量线性减少。这与计算单元与训练时间之间具有亚线性关系的通用GPU集群不同。
Cerebras声称,由于内存和带宽限制,类似的工作不可能在2000个NVIDIA A100 GPU的集群上进行。
仙女座超级计算机的关键技术规范
Andromeda基于Cerebras的CS-2系统构建,共包括1350万个人工智能优化计算核心和18178个第三代AMD EPYC处理器。
据报道,仙女座在GPT语言模型中提供了近乎线性的缩放。[点击放大]
这台超级计算机还采用了晶圆级集群和重量流,由Cerebras的MemoryX和SwarmX技术支持。仙女座产生了1 EB的人工智能计算和120 PB的16位半精度的密集计算。
CS-2系统
仙女座拥有16个CS-2系统,每个系统都有一个Cerebras‘Wafer Scale Engine 2(WSE-2)处理器——一个46225毫米的处理器2.拥有2.6万亿个7nm晶体管的处理器。据报道,WSE-2是“地球上最大的处理器”。支持软件平台开箱即用地集成了PyTorch和TensorFlow。

小脑CS-2
以下是CS-2的其他一些规格:
- 85万AI优化计算核心
- 40 GB集成SRAM
- 20 PB/s内存带宽
- 220 PB/s互连带宽
- 1.2 TB/s I/O
- 12 x 100 GB以太网链路
- 15个机架单元(RU)
- 水冷式
晶圆级集群
晶圆级集群通过在单个处理器内拟合包括计算组件和参数组件的整个神经网络,最大限度地利用了WSE-2的大小。晶圆级集群还利用了数据并行性。分配集群数量与设置参数一样简单明了。

只需一次按键,用户就可以在CS-2系统集群中进行分布式训练。
这消除了在分布式系统上规划和配置训练模型的需要,因为分布式系统可能复杂、缓慢且耗电。此外,由于人工智能计算是在单个设备上完成的,因此训练速度更快。
重量流
Cerebras的MemoryX和StreamX技术支持重量流。MemoryX管理芯片外模型权重的存储,包括将权重流式传输回处理器上的模型,计算更新的权重,以及定时交付。MemoryX可以支持2000亿至120万亿个参数,并声称其速度与芯片上一样快。
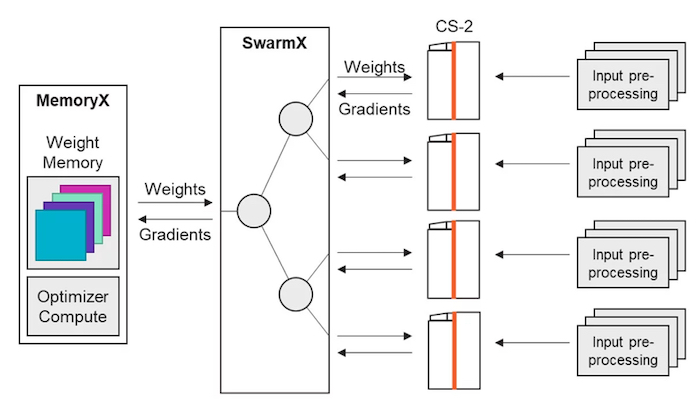
CS-2s集群的重量流。
SwarmX是MemoryX和CS-2系统之间存在的另一种支持技术。它将权重分配给CS-2系统,并将得到的梯度提供回MemoryX。这两种技术共同实现了训练过程中的重量分流。
研究人员利用仙女座的超级计算
Cerebras已经为几个研发和学术机构提供了仙女座的各种应用。
阿贡国家实验室使用仙女座来开发基因转换器,使用GPT3-XL模型和整个新冠肺炎基因组。与此同时,JasperAI正在使用仙女座来训练模型,这些模型将用于为广告、营销和书籍等书面材料编写副本。
Andromeda托管在加利福尼亚州的Colovore数据中心,Cerebras现在可以访问更多的潜在客户。
使用的所有图像均由Cerebras提供