
NVIDIA在Hot Chips上分享Grace CPU和Hopper GPU的详细信息
在今年的热门芯片大会上,NVIDIA对其最新的计算旗舰处理器进行了更多的介绍。2022年8月24日,杰克·赫兹
在三月份的GTC活动上,NVIDIA推出了一系列新技术,如Grace CPU、Hopper GPU和NVLINK-C2C互连架构。
现在,NVIDIA正在为我们提供有关这些版本的更深入的信息和技术细节。在本周的Hot Chips 34大会上,多位NVIDIA发言人上台,每一位发言人都让业界更深入地了解是什么让每一个版本如此特别。
在本文中,我们将了解NVIDIA每一项新旗舰技术发布的一些令人兴奋的细节。
宽限CPU和缓存一致性
NVIDIA今年发布的最令人兴奋的产品之一是其Grace CPU“超级芯片”。在本周的演示中,NVIDIA杰出工程师NVIDIA Jonathon Evans上台透露了有关超级芯片的更多细节。
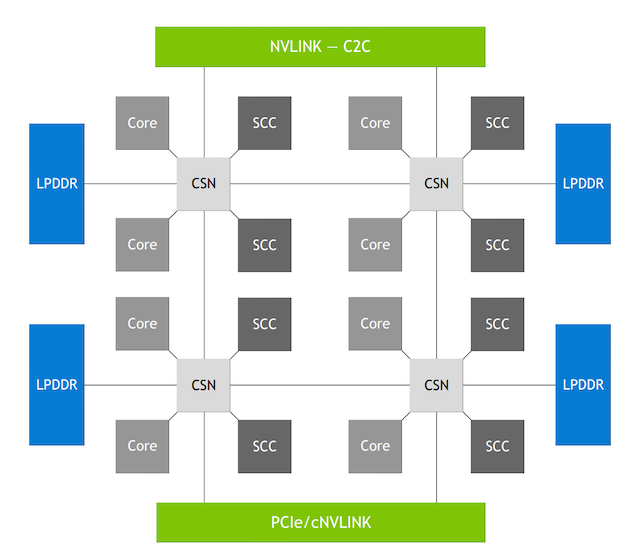
NVIDIA的可扩展一致性结构(SCF)。图像由NVIDIA提供
Grace设计用于数据中心计算,特别是人工智能处理,同时优化设备和系统级别的功耗和性能。正如演示中所讨论的,在这一追求中,Grace最重要的方面之一是使用NVIDIA的可扩展一致性结构(SCF)。
SCF是一种网状互连架构,连接NVIDIA结构和分布式缓存设计。具体而言,SCF旨在连接Grace CPU内的不同内部子系统,包括内存、CPU内核和I/O。为了实现这一点,NVIDIA告诉我们,SCF可以实现2335.6 GB/s的双节带宽,支持高达117 MB的L3缓存,并且可以扩展到72+个内核。
除此之外,SCF还提供了许多有用的功能,例如具有划分系统资源的Arm标准。有了这个标准,Grace可以为每个请求内存的实体分配分区ID,SCF缓存资源可以在不同的ID之间进行分区。具体来说,SCF可以对缓存容量和内存带宽进行分区,而性能监视器组则监视资源使用情况。
Hopper GPU:流式多处理器
除了Grace之外,NVIDIA的CPU和系统架构师Jack Choquette还做了一个演示,阐明了Hopper GPU的一些技术细节。
Choquette演讲的重点之一是Hopper的新型流式多处理器(SM)架构。在Hopper中,NVIDIA推出了一种新组件,称之为“SM到SM网络”,这是一种高带宽通信结构,用于连接Hopper图形处理集群内的资源。
这个想法是允许流式多处理器直接通信,而不需要访问内存。这大大降低了处理集群的延迟,使FP32和FP64 FMA速度提高了2倍,还支持高达256 KB的L1缓存。
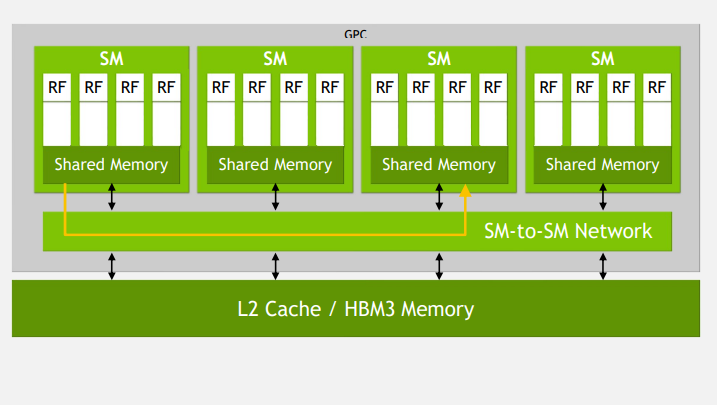
Hopper的SM到SM网络。图像由NVIDIA提供
除此之外,讲座还涵盖了一些有趣而重要的概念,这些概念指导了Hopper的设计。
对话的一大主题围绕着NVIDIA如何利用空间和时间局部性展开,其中网格化架构和线程块有助于NVIDIA的CUDA实现更低的延迟和更高的并行性能。
其他概念包括NVIDIA使用Hopper作为异步GPU,通过允许线程以不同的速率执行来提高性能。这在性能上提供了很大的好处,因为空闲时间被最小化,从而可以充分利用每个单元,并可以优化并行计算。
用于芯片间集成的NVLink
最后,Hopper体系结构的一个关键构建块是NVLink-C2C互连技术的引入。在NVIDIA系统架构师Alexander Ishii和Ryan Wells的演讲中,NVLink的重要性得到了进一步讨论。
NVIDIA对设计师的想法是开发能够在一个集群中利用数百个Hopper GPU的计算平台,而要实现这一点,需要高速的设备到设备互连。对于Hopper来说,这种互连是NVLink-C2C,根据谈话,主要好处是比PCIe更快的速率(每通道100 Gbps,而每通道23 Gbps),以及比传统网络更低的开销。
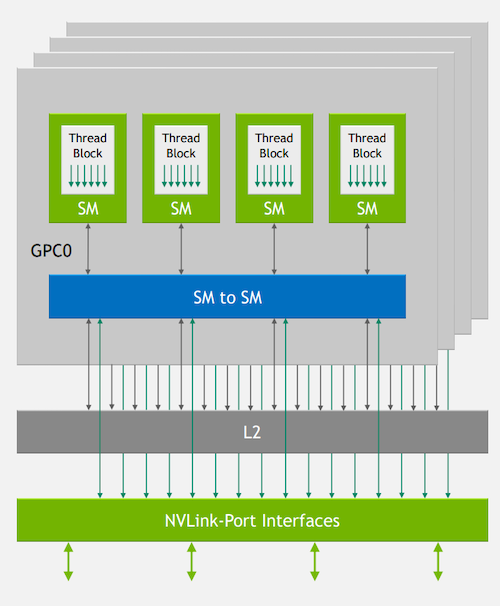
NVLink端口接口是Hopper体系结构的一个关键方面。图像由NVIDIA提供
例如,NVIDIA的交钥匙AI HPC数据中心解决方案是一个名为SuperPOD的大型计算集群。在SuperPOD体系结构中,可以找到32台DGX H100服务器和18台NVLink交换机,它们提供56.7 TB/s的NVLink网络平分带宽,并可以提供高达1 ExaFLOP的AI性能。根据NVIDIA的说法,只有借助NVLink互连技术,才能实现这种性能。