
Sklearn2ONNX AI范例分享:风扇堵塞侦测
本文分享沒有AI背景的工程师,在使用NanoEdge AI Studio快速训练风扇异常侦测的模型的方法。...
本文分享沒有AI背景的工程师,在使用NanoEdge AI Studio快速训练风扇异常侦测的模型的方法。
此模型是依马达控制板的电流讯号,侦测风扇滤网的堵塞百分比。当风扇堵塞时,马达的电流讯号波型与一般情况不同,但传统演算法很难侦测到差异。因此,机器学习演算法便成为解决此问题的绝佳选择。在训练模型时,通常会使用scikit-learn函式库,因此,本文将阐述自行训练机器学习模型及使用 STM32Cube.AI 部署到相同装置上的方式,以便使用者比较两者之间的差异。

|
NanoEdge AI Studio为端对端工具,可预先处理部分资料,再进行训练与媒合演算法;而STM32Cube.AI则会需要工程师具备完整的AI模型开发经验。
硬体与软体前置准备

|
P-NUCLEO-IHM03马达控制套件用于驱动风扇,是由NUCLEO-G431RB主机板、马达控制扩充板与无刷马达所组成。
在进行软体前置准备时,需先设定Anaconda环境,并安装scikit-learn、pandas和ONNX等必要函式库。
然后,再依建立AI专案的关键步骤,逐步建立以STM32Cube.AI为基础的专案。
首先,使用者需要收集建立机器学习模型所需的资料。在此资料集当中(训练资料集),部分将用于模型训练,典型比例为80%,而另一部分(测试资料集)用于日后评估所建模型的效能,典型比例为20%。
第二步,使用者需要「标记」资料。因为决策树模型是以模型建立者所标记的分类为基础,因此,机器需要知道所收集到之资料的类別,例如「跑步」、「行走」、「静止」等。
分类是指使用者依照其认为重要的属性将资料分组,也就是机器学习领域中的「类別(class)」。
接下来,使用者要利用已准备好的资料集训练机器学习模型,也就是「拟合(fitting)」。此步骤的结果准确度有极大程度取决于资料之内容与数量。
第四步,使用者要将训练完毕的机器学习模型内嵌至系统。若是电脑执行的机器学习,使用者可使用Python函式库直接执行模型;若机器学习位于MCU等装置上,则可在实作前将此函式库转换成C语言程式码;若为MEMS MLC等硬体配缐方案,实作前可使用UNICO-GUI专用软体,将函式库先转换为暂存器设定。
最后一步为验证机器学习模型,如果验证结果不符预期,使用者必须确认并改善上述步骤。

|
首先,先匯入需要的函式库
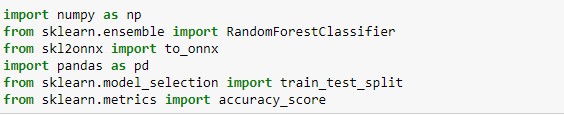
|
为了方便比较,这边使用上一次NanoEdge AI Studio训练模型中所使用的资料集。本文作者使用pandas,并从csv档读取资料,并将其用于训练模型。
在开始训练模型前可以先输出(print)资料集的形状以瞭解内容。

|
此资料集是由119笔资料所组成,共有128种特徵,且最后一个资料栏为资料标籤。
接着,我们将资料集分为训练集及测试集,训练集用以训练模型,佔资料集的80%,而测试集是用以检查模型一般化能力,比重为20%。

|
资料集备妥即可开始训练模型。

|
训练结束后可在测试集上验证该模型的效能。可以看到,模型在测试集上可达到约83%的准确率。

|
最后,储存训练后的模型会取得名为random_forest.onnx 的ONNX格式档案。

|
以下为使用Netron模型可视化工具检视的模型架构:

|
经过STM32Cube的整合,STM32Cube.AI 使用者能有效率地将模型移转至多样化的STM32微控制器系列中,而且类似模型也同样适用于不同产品,能够在STM32产品组合中轻松移转。
此外挂程式可扩充STM32CubeMX的功能,自动转换预先训练的人工智慧演算法,并将其产生的最佳化资料库整合至使用者专案当中,不需手动撰写程式码,并且能将深度学习解决方案嵌入各种STM32微控制器产品组合中,赋予产品智慧功能。
STM32Cube.AI提供各种深度学习框架的原生支援,例如Keras、TensorFlow Lite、ConvNetJs,也支援像是PyTorch、Microsoft Cognitive Toolkit、MATLAB等,所有可匯出为ONNX标准格式的框架。
此外,STM32Cube.AI还支援来自大量ML开放原始码函式库scikit-Learn的标准机器学习演算法,例如Isolation Forest、支援向量机器(Support Vector Machine,SVM)、k-means。

|
现在已经准备好将模型部署至MCU了。本篇採STM32Cube.AI的CLI模式,可使用以下指令将模型转换成最佳化C语言程式码:
Stm32ai generate –m random forest.onnx
若转换成功,以下讯息将会出现。

|
在资料夹stm32ai_output中,可以看到下方产生出来的档案。其中,network.c/.h保留模型拓扑的资讯,而network_data.c/.h则会记录模型权重的资讯。
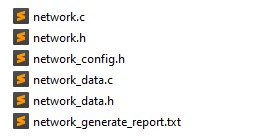
|
此时,产生的模型也已经可以整合至STM32专案中。当使用CLI模式时,STM32Cube.AI的执行阶段需要手动新增至专案中,以利呼叫network.h中的函式执行模型。
STM32Cube.AI也有更轻松整合AI模型的方式,若专案是以ioc档案着手,便可将AI模型新增至CubeMX程式码产生阶段,一同产生程式码。

|
如下图所示,启用CubeMX的AI功能。
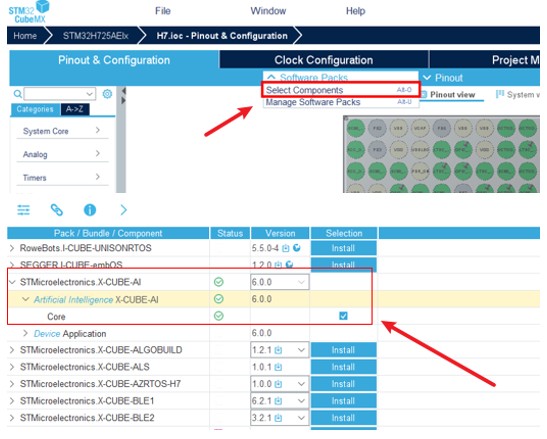
|
将AI模型整合至专案当中。

|
如此一来,在产生程式码时,AI模型会转译成最佳化C语言程式码,而且STM32Cube.AI执行阶段的对应版本也会一併整合至专案中。
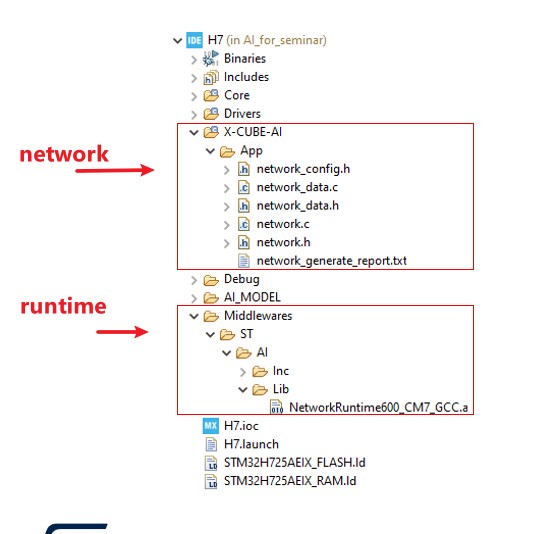
|
藉由这样的方式,模型可整合至专案,且不会产生任何差错。从以上两种方法可以发现两者差异在于NanoEdge AI Studio较简易,且更有效率,而STM32Cube.AI则较为灵活、可自订空间较大。