
如何在MCU上实现物联网(AIoT)
在我的上一篇文章,我强调了物联网设备中越来越多的人工智能(AI)创造智能“AIoT”设备的增长趋势,各种应用程序都从这些智能设备中受益。这些产品从数据中学习,并在没有人为干预的情况下做出自主决策,从而使产品与环境具有更合乎逻辑、更人性化的互...
在我的上一篇文章,我强调了物联网设备中越来越多的人工智能(AI)创造智能“AIoT”设备的增长趋势,各种应用程序都从这些智能设备中受益。这些产品从数据中学习,并在没有人为干预的情况下做出自主决策,从而使产品与环境具有更合乎逻辑、更人性化的互动。
人工智能和物联网的结合为MCU(微控制器)开辟了新市场。它已经启用了越来越多的新应用程序和用例,可以使用简单的MCU和AI加速来促进智能控制。这些支持人工智能的MCU提供了用于计算的DSP能力和用于推理的机器学习(ML)的独特组合,目前正被用于关键字识别、传感器融合、振动分析和语音识别等各种应用。更高性能的MCU能够在视觉和成像领域实现更复杂的应用,如人脸识别、指纹分析和自主机器人。
人工智能技术
以下是一些在物联网设备中实现人工智能的技术:
机器学习(ML):机器学习算法基于代表性数据建立模型,使设备能够在没有人为干预的情况下自动识别模式。ML供应商提供训练模型所需的算法、API和工具,然后这些模型可以构建到嵌入式系统中。然后,这些嵌入式系统使用预先训练的模型来基于新的输入数据来驱动推断或预测。应用程序示例包括传感器集线器、关键字发现、预测性维护和分类。
深度学习:深度学习是一类机器学习,它通过使用多层神经网络来训练系统,从复杂的输入数据中逐步提取更高层次的特征和见解。深度学习处理非常大、多样和复杂的输入数据,使系统能够迭代学习,从而提高每一步的结果。使用深度学习的应用程序示例有图像处理、用于客户服务的聊天机器人和人脸识别。
自然语言处理:NLP是人工智能的一个分支,它使用自然语言处理系统和人类之间的交互。NLP帮助系统理解和解释人类语言(文本或语音),并在此基础上做出决策。应用的例子有语音识别系统、机器翻译和预测打字。
计算机视觉:机器/计算机视觉是一个人工智能领域,它训练机器收集、解释和理解图像数据,并根据这些数据采取行动。机器从相机中收集数字图像/视频,使用深度学习模型和图像分析工具准确识别和分类物体,并根据他们“看到的”采取行动。例如制造装配线上的故障检测、医疗诊断、零售店的人脸识别和无人驾驶汽车测试。
MCU上的AIoT
在过去,人工智能是MPU和GPU的职权范围,它们拥有强大的CPU核心、大量的内存资源和用于分析的云连接。然而,近年来,随着边缘智能化的增加,我们开始看到MCU被用于嵌入式AIoT应用程序。向边缘的移动是由延迟和成本因素驱动的,并涉及到将计算移动到更接近数据的位置。基于MCU的物联网设备上的人工智能允许实时决策和更快地响应事件,并具有更低的带宽要求、更低的功耗、更低的延迟、更低的成本和更高的安全性等优势。AIoT是由最近的MCU的更高计算能力以及更适合这些终端设备中使用的资源受限MCU的瘦神经网络(NN)框架的可用性实现的。
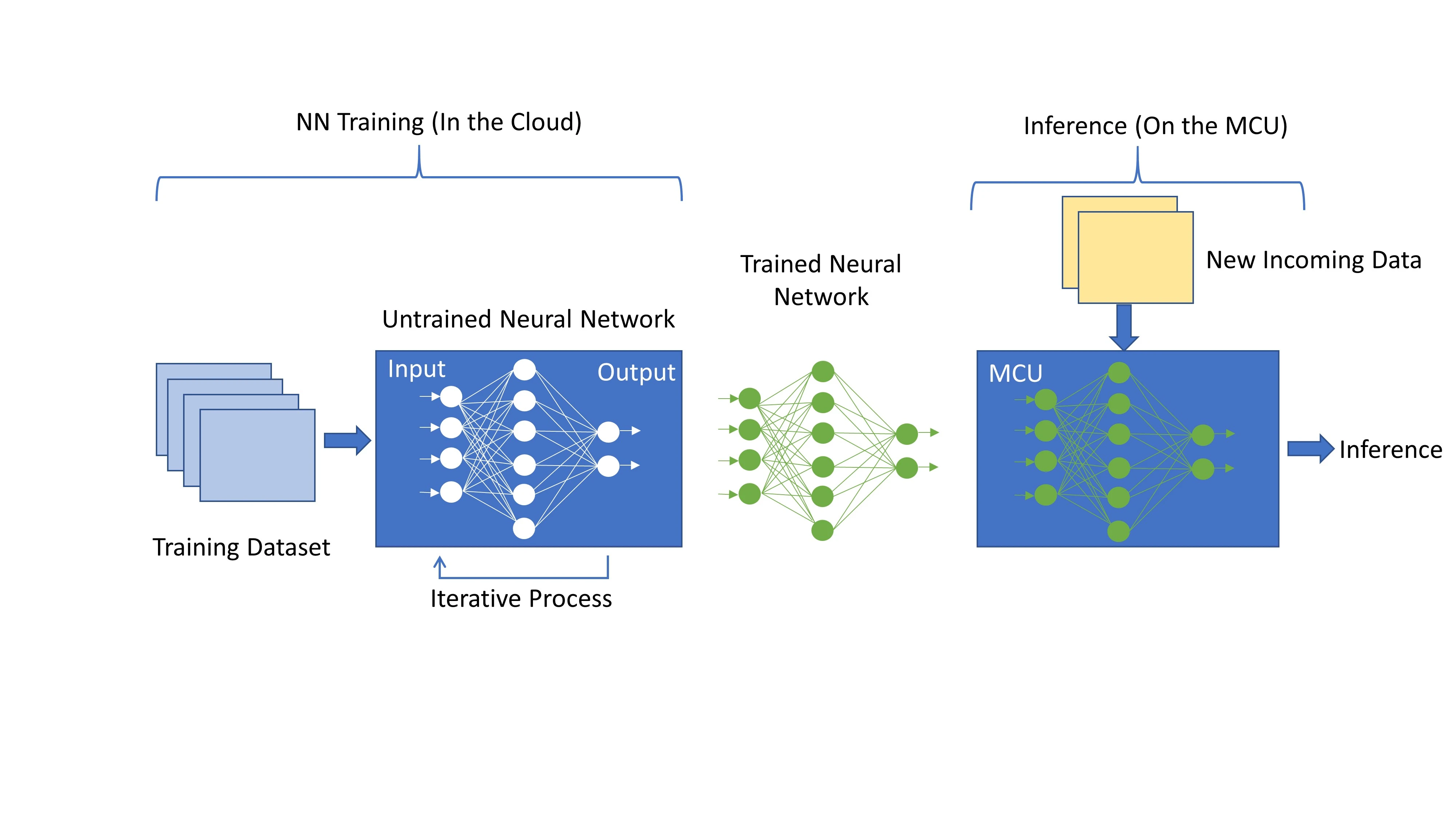
神经网络是节点的集合,按层排列,从前一层接收输入,并根据输入的加权和偏置和生成输出。此输出将沿着其所有传出连接传递到下一层。在训练期间,训练数据被馈送到网络的第一层或输入层,并且每一层的输出被传递到下一层。最后一层或输出层产生模型的预测,将其与已知的预期值进行比较,以评估模型误差。训练过程包括在每次迭代时使用称为反向传播的过程来细化或调整网络的每一层的权重和偏差,直到网络的输出与期望值密切相关。换句话说,网络从输入数据集迭代地“学习”,并逐步提高输出预测的准确性。
神经网络的训练需要非常高的计算性能和内存,并且通常在云中进行。在训练之后,这个预先训练的神经网络模型被嵌入到MCU中,并作为基于其训练的新传入数据的推理引擎。
<img data-lazy-fallback="1" decoding="async" src="https://uploads.9icnet.com/images/aritcle/20230419/Fig-1-Renesas-part-2-neural-network-training-and-inference-.jpg" alt="Fig 1 - Renesas part 2 - neural network training and inference" class="wp-image-4470387" width="1000" height="563" srcset="https://uploads.9icnet.com/images/aritcle/20230419/Fig-1-Renesas-part-2-neural-network-training-and-inference-.jpg 4000w, https://uploads.9icnet.com/images/aritcle/20230419/Fig-1-Renesas-part-2-neural-network-training-and-inference-.jpg?resize=300,169 300w, https://uploads.9icnet.com/images/aritcle/20230419/Fig-1-Renesas-part-2-neural-network-training-and-inference-.jpg?resize=768,432 768w, https://uploads.9icnet.com/images/aritcle/20230419/Fig-1-Renesas-part-2-neural-network-training-and-inference-.jpg?resize=1024,576 1024w, https://uploads.9icnet.com/images/aritcle/20230419/Fig-1-Renesas-part-2-neural-network-training-and-inference-.jpg?resize=1536,864 1536w, https://uploads.9icnet.com/images/aritcle/20230419/Fig-1-Renesas-part-2-neural-network-training-and-inference-.jpg?resize=2048,1152 2048w" sizes="(max-width: 1000px) 100vw, 1000px">
图1:神经网络训练和推理
这种推理生成需要比模型的训练低得多的计算性能,因此适合于MCU。这种预先训练的NN模型的权重是固定的,可以放在闪存中,从而减少了所需的SRAM数量,并使其适用于资源受限的MCU。
MCU上的实施
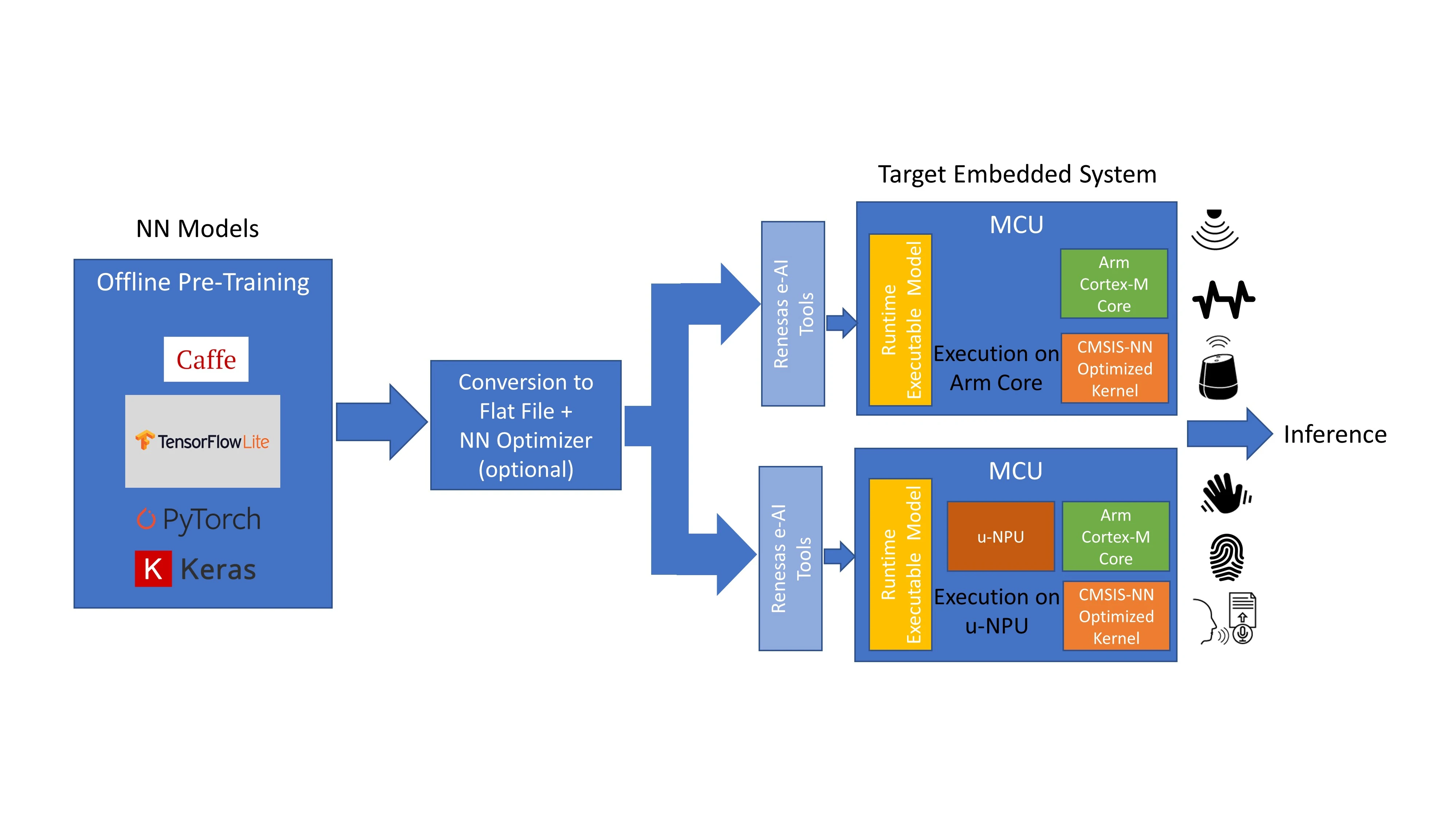
在MCU上实现AIoT涉及几个步骤。最常见的方法是使用可用的神经网络(NN)框架模型之一,如Caffe或Tensorflow Lite,适用于基于MCU的终端设备解决方案。机器学习的神经网络模型的培训是由人工智能专家使用人工智能供应商提供的工具在云中完成的。神经网络模型的优化和MCU上的集成是使用人工智能供应商和MCU制造商的工具进行的。使用预先训练的NN模型在MCU上进行推理。
该过程的第一步是完全离线完成的,包括从终端设备或应用程序捕获大量数据,然后用于训练神经网络模型。模型的拓扑结构由人工智能开发人员定义,以最大限度地利用可用数据并提供应用程序所需的输出。神经网络模型的训练是通过迭代地将数据集传递到模型中来完成的,目的是连续地最小化模型输出处的误差。神经网络框架中有一些工具可以帮助实现这一过程。
在第二步中,这些针对关键词识别或语音识别等特定功能进行优化的预训练模型被转换为适合MCU的格式。这个过程的第一步是使用AI转换器工具将其转换为平面缓冲文件。这可以选择性地通过量化器运行,以便减小大小并优化MCU。然后将该平面缓冲文件转换为C代码,并将其作为运行时可执行文件传输到目标MCU。
该MCU配备了经过预训练的嵌入式人工智能模型,现在可以部署在终端设备中。当新数据进入时,它会在模型中运行,并根据训练生成推理。当新的数据类出现时,NN模型可以被发送回云中进行重新训练,并且新的重新训练的模型可以在MCU上编程,可能通过OTA(空中传送)固件升级。
有两种不同的方式可以构建基于MCU的人工智能解决方案。出于本讨论的目的,我们假设在目标MCU中使用Arm Cortex-M内核。
<img data-lazy-fallback="1" decoding="async" loading="lazy" src="https://uploads.9icnet.com/images/aritcle/20230419/Fig-2-Renesas-part-2-AI-implemetation-on-MCUs.jpg" alt="Fig 2 - Renesas part 2 - AI implemetation on MCUs" class="wp-image-4470388" width="1000" height="563" srcset="https://uploads.9icnet.com/images/aritcle/20230419/Fig-2-Renesas-part-2-AI-implemetation-on-MCUs.jpg 4000w, https://uploads.9icnet.com/images/aritcle/20230419/Fig-2-Renesas-part-2-AI-implemetation-on-MCUs.jpg?resize=300,169 300w, https://uploads.9icnet.com/images/aritcle/20230419/Fig-2-Renesas-part-2-AI-implemetation-on-MCUs.jpg?resize=768,432 768w, https://uploads.9icnet.com/images/aritcle/20230419/Fig-2-Renesas-part-2-AI-implemetation-on-MCUs.jpg?resize=1024,576 1024w, https://uploads.9icnet.com/images/aritcle/20230419/Fig-2-Renesas-part-2-AI-implemetation-on-MCUs.jpg?resize=1536,864 1536w, https://uploads.9icnet.com/images/aritcle/20230419/Fig-2-Renesas-part-2-AI-implemetation-on-MCUs.jpg?resize=2048,1152 2048w" sizes="(max-width: 1000px) 100vw, 1000px">
图2:使用离线预训练模型在MCU上实现人工智能。
在第一种方法中,转换后的NN模型在Cortex-M CPU内核上执行,并使用CMSIS-NN库进行加速。这是一种简单的配置,可以在没有任何额外硬件加速的情况下进行处理,适用于更简单的人工智能应用,如关键词识别、振动分析和传感器集线器。
一个更复杂、更高性能的选项包括在MCU上包括NN加速器或微神经处理单元(u-NPU)硬件。这些u-NPU加速了资源受限的物联网终端设备中的机器学习,并可能支持压缩,从而降低模型的功率和大小。它们支持能够完全执行大多数常见NN网络的运营商,用于音频处理、语音识别、图像分类和对象检测。u-NPU不支持的网络可以回退到主CPU核心,并由CMSIS-NN库加速。在这种方法中,神经网络模型是在uNPU上执行的。
这些方法展示了在基于MCU的设备中引入人工智能的几种方法。随着MCU将性能边界推向更高的水平,更接近于MPU的预期,我们预计将开始看到直接在MCU上构建的完整人工智能功能,包括轻量级学习算法和推理。
边缘的人工智能是未来
未来,人工智能在资源受限的MCU上的实现将呈指数级增长,随着MCU突破性能边界,模糊MCU和MPU之间的界限,越来越多适用于资源受限设备的“瘦”神经网络模型可用,我们将继续看到新的应用程序和用例出现。
未来,随着MCU性能的提高,除了推理之外,我们可能还会看到轻量级学习算法的实现,直接在MCU上运行。这将为MCU制造商开辟新的市场和应用,并将成为他们的一个重大投资领域。

<img data-lazy-fallback="1" decoding="async" loading="lazy" src="https://uploads.9icnet.com/images/aritcle/20230419/Kavita-Char-Renesas.jpg?w=640" alt="Kavita Char - Renesas" class="wp-image-4470070" width="150" height="150" srcset="https://uploads.9icnet.com/images/aritcle/20230419/Kavita-Char-Renesas.jpg 800w, https://uploads.9icnet.com/images/aritcle/20230419/Kavita-Char-Renesas.jpg?resize=150,150 150w, https://uploads.9icnet.com/images/aritcle/20230419/Kavita-Char-Renesas.jpg?resize=300,300 300w, https://uploads.9icnet.com/images/aritcle/20230419/Kavita-Char-Renesas.jpg?resize=768,768 768w" sizes="(max-width: 150px) 100vw, 150px">
卡维塔字符是美国瑞萨电子公司的高级产品营销经理。她在软件/应用工程和产品管理方面拥有超过20年的经验。凭借在物联网应用、MCU和无线连接方面的丰富经验,她现在负责Renesas下一代基于Arm的高性能MCU和解决方案的定义和概念发布管理。