
TinyML峰会:用数字内存计算增强NPU
在2023年TinyML峰会上,STMicroelectronics介绍了内存计算的好处,特别是对神经处理单元的好处。2023年5月1日作者:杰克·赫兹
TinyML采用大型机器学习(ML)模型,使其能够在资源受限的小型微控制器上运行。TinyML设备以低功耗长时间运行为目标,需要极其高效的硬件和优化的软件。TinyML基金会每年都会举办TinyML峰会,这是一次行业领导者的聚会,讨论行业的现状和未来。
最近,TinyML 2023年峰会向公众开放了2023年的峰会。其中一次会议来自意法半导体,意法半导体技术总监Danilo Pau在会上发表了题为“用数字内存计算增强神经处理单元(NPU)”的演讲
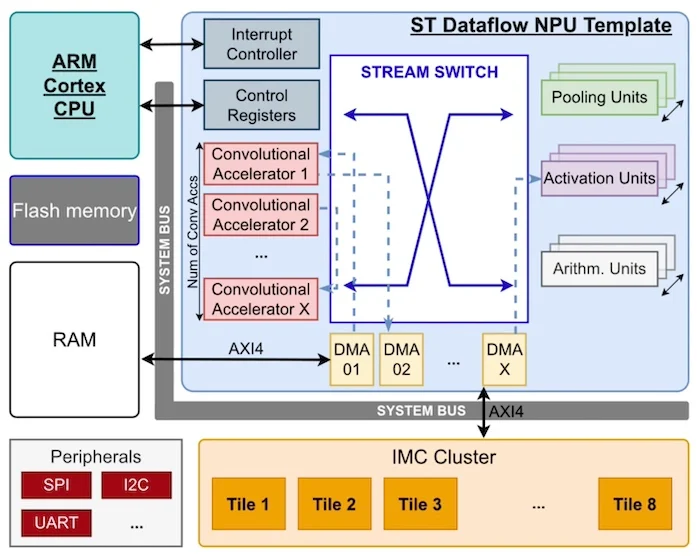
ST的数据流NPU模板。屏幕截图由意法半导体提供
根据ST的说法,在本文中,我们将讨论内存计算体系结构的优点以及这种计算风格对NPU的主要好处。
TinyML权衡:复杂计算与功率
一些最著名的ML模型在具有几乎无限计算和内存资源的大型数据中心中运行。采用相同的ML功能,但将其应用于小型电池供电的边缘设备,这是一个重大的设计挑战。
TinyML硬件中存在的折衷是实现ML模型所需的计算能力,同时将功耗保持在最低限度。正如Pau在演讲中所解释的那样,“一方面,我们希望实现非常高的计算能力,但另一方面我们希望消耗几乎为零的功率,并以尽可能低的成本制造芯片。”
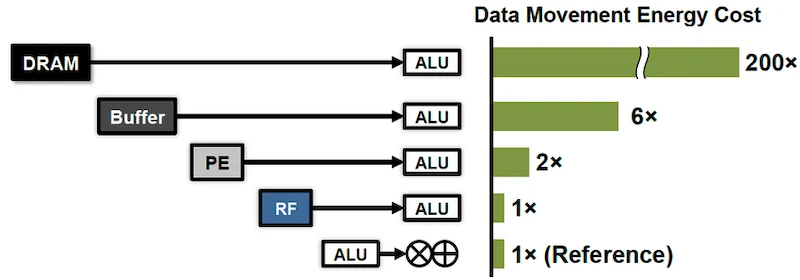
数据移动的能源成本。图片由Shi等人提供。
ML计算在传统计算体系结构中消耗了大量的能量,因为这些操作涉及数据负载。ML模型中可能涉及数十亿个权重和参数,计算这些算法需要将数据进出内存,大量移动到处理核心。
这种数据移动是经典冯·诺依曼体系结构的基本限制,并导致ML计算效率低下。
内存计算意味着更少的数据移动和功耗
滚动以继续内容
为了避开冯·诺依曼体系结构的基本限制,意法半导体正转向内存计算作为一种解决方案。内存计算改变了计算的范式,从数据和计算在空间上分离到数据和计算发生在同一个地方。
Pau解释道:“将数据进出内存传输到任何硬件加速器都是一个非常谨慎的设计点,因为尽管硬件加速器可以提供非常高的计算能力,但它最终可能会受到与内存交易效率的限制。我们需要打破内存墙。”
通过这种方式,内存中的计算避免了与数据移动相关的功耗,并使TinyML硬件更加高效。
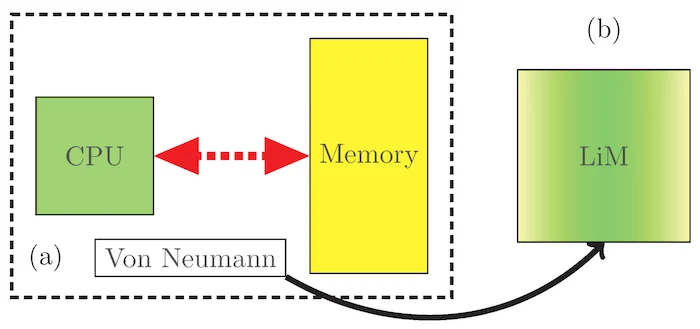
内存计算消除了冯·诺依曼的瓶颈。图片由Coluccio等人提供。
除了内存计算之外,意法半导体也在追求降低计算精度以提高能源效率的想法。这就是TinyML中量化背后的想法:通过降低数据精度,比如从32位FP到8位INT,ML模型可以在总体上显著减少的数据上运行。这显著降低了功耗,而不会对模型精度产生巨大影响。
关于这一点,Pau说:“想象一下,我们可以在1位权重和1位激活的范围内设计二进制神经网络。我们将解锁非常高效、低功耗、低复杂度和高并行性的系统,这将是非常棒的。”
ST为TinyML推出低功耗NPU
基于这些想法,意法半导体正在为TinyML开发一种新的实验性低功耗NPU。
该芯片本身围绕600 MHz Arm Cortex-M4处理核心构建,具有八个集成数字内存计算(DIMC)SRAM瓦片。该系统具有4个CNN加速器;张量直接存储器存取(DMA),有助于存储器转移;以及51kB的共享SRAM。
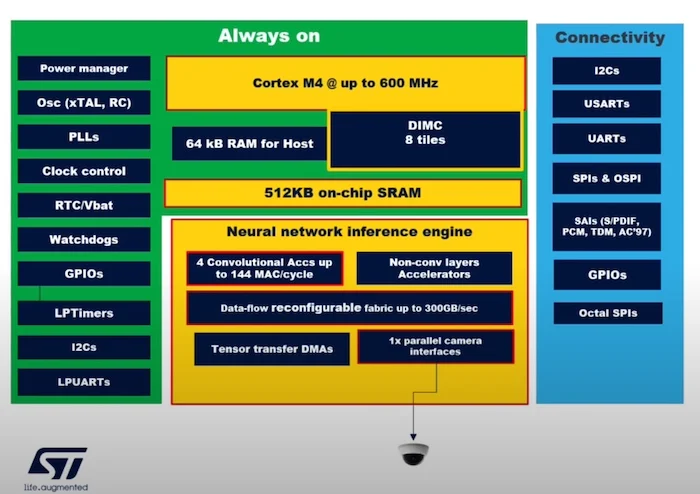
内存计算NPU中ST的框图。屏幕截图由意法半导体提供
DIMC瓦片建立在40nm节点上,可以执行二进制内存计算,从而大幅提高二进制层的计算效率。ST通过运行实时面部检测算法验证了该系统,他们发现测试芯片的运行延迟为3毫秒。重要的是,DIMC子系统在二进制计算中实现了100 TOPS/W的峰值效率。总的来说,该系统被证明实现了比传统NPU实现高40倍的TOPS/W。
有了这一点,ST已经证明了内存计算和精度降低带来的主要好处。通过将NPU的功率效率提高40倍,ST的工作可能会对TinyML硬件的未来产生重大影响。