
人工智能初创公司斥资2700万美元将边缘存储计算商业化
Axelera人工智能声称已经将整个服务器的计算能力集中到一个芯片上,其功率和价格仅为当今人工智能硬件的一小部分。2022年11月1日作者:Darshil Patel
欧洲人工智能初创公司Axelera AI最近获得了2700万美元的资金,用于将其人工智能加速平台商业化。首都将支持其第一代人工智能硬件和软件的推出和大规模生产,将多核内存计算与自定义数据流架构相结合。
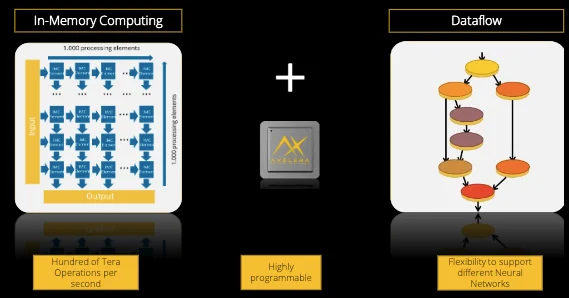
Axelera人工智能加速平台的描述。图片由Axelera AI提供
新平台旨在支持边缘的机器学习,使人工智能更加高效和可访问。该工具将帮助那些希望开发基于人工智能的产品的企业家,瞄准工业4.0等市场。
阿克塞尔拉人工智能的起源
认识到可用的边缘计算系统效率低下且成本高昂,Axelera AI的创始团队来自imec的Fabrizio Del Maffea和来自IBM苏黎世实验室的Evangelos Eleftheriou,以及他们来自这两个机构的同事,开始重新思考边缘的人工智能硬件。2021年7月,他们创立了Axelera AI,将其技术商业化。同年12月,他们推出了该公司的第一款测试台芯片Thetis Core。
Thetis Core在小于9平方毫米的区域内提供每秒39.3万亿次操作(TOPs/s)的速度和每瓦14.1万亿次操作的效率。该芯片利用了该公司独特的内存计算技术。Axelera人工智能还创建了软件堆栈,允许客户在其人工智能平台上运行神经网络,而无需再培训。
本周,Axelera AI获得了2700万美元的A系列资本,来自imec.xpand和比利时联邦控股投资公司。该公司目前正在开发Thetis Core芯片和相关软件,用于安全、零售、机器人和工业4.0等应用。此外,该公司计划今年将其研发办事处扩大到美国和台湾。
边缘存储计算的优势
边缘计算是指去中心化的数据处理或硬件本身的处理。这种方法减少了硬件和中央IT网络之间的通信延迟。尽管人工智能的速度处于边缘,但这些应用程序需要更强大、更高效的硬件架构来保持低延迟和低功耗。
当前的冯·诺依曼体系结构将处理单元和存储器单元分开。正如Axelera AI的创始人所注意到的那样,这种传统的计算架构需要在这些单元之间来回移动大量数据,从而增加了延迟和功耗。或者,内存内计算架构处理内存本身中的数据,从而大幅削减与数据传输相关的时间和功率。
使用Crossbar阵列进行内存计算
Axelera AI使用了一种流行的内存计算架构,其中包括内存设备的交叉阵列。这些交叉阵列可以存储并执行矩阵向量乘法(MVM),这是所有深度学习操作的核心。
横杆阵列由平行的金属线组成,顶部和底部电极彼此垂直。存储器存储元件,例如电容器或忆阻器,连接在线路的交叉处。读取和写入操作的速度取决于存储器设备的类型。Axelera AI的研究人员报告称,SRAM、闪存和所有忆阻器存储器都适用于MVM操作。
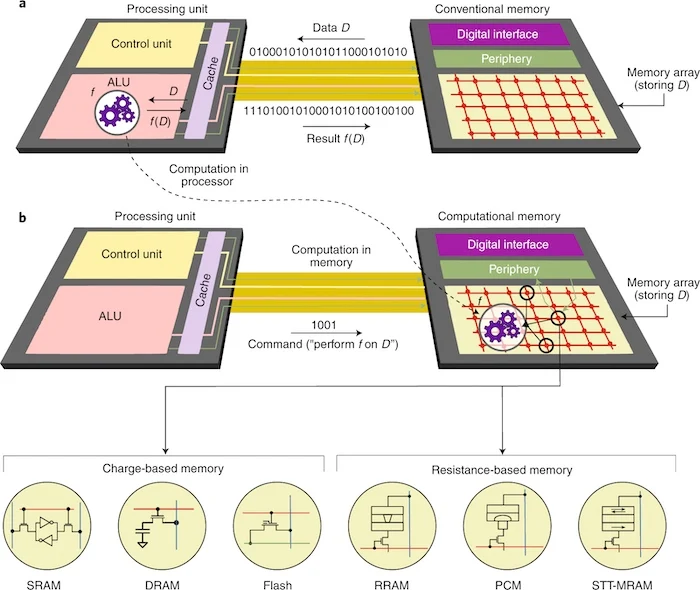
内存计算体系结构的说明。图片由Axelera AI提供
研究人员正在研究多核内存计算,这取决于多种特性,如优化的内存层次结构、良好的平衡结构、微调的量化流、优化的权重映射策略以及通用的编译器和软件工具链。Axelera AI将其内存计算技术与定制数据架构相结合,实现高吞吐量、高效性和准确性。
Thetis核心芯片
在imec.IC-link(台积电价值链聚合器)的支持下,Axelera AI推出了Thetis Core测试芯片,以展示其内存计算的高性能。
Thetis Core于2022年5月发布,在不到9平方毫米的INT8精度下,可执行39.3次TOPs/s,效率为14.1次TOP/W。它证明了33 TOPs/W的峰值能量效率。根据Axelera AI的数据,通过增加时钟频率,峰值吞吐量可以达到48.16个TOPs。

Thetis核心芯片。图片由Axelera AI提供
该公司计划在其第一款产品中集成多个版本的内存计算引擎,该产品计划于2023年初与选定的客户和合作伙伴一起推出。